
Self-taught Go computer is even better
It turns out that a Go computer teaches itself the game to an even higher standard than an artificial intelligence which learns from humans. Google company DeepMind built such an auto-adaptive computer, which then beat its predecessor AlphaGo by 100-0.
Earlier this year, AlphaGo convincingly defeated the world's best human Go player (read: 'Massive victory for Go player computer'). That program trained using data from some 100,000 human-played Go games, developing its own tactics based on this information.
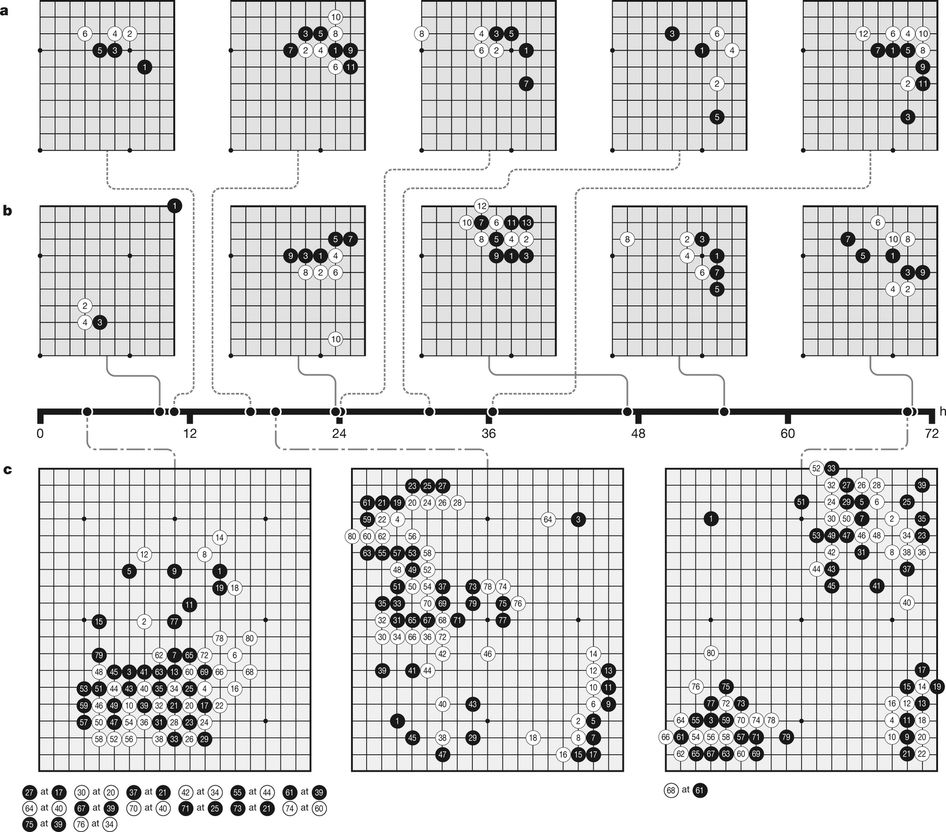
The new algorithm, which DeepMind calls AlphaGo Zero, tackles things differently. The input is simply the Go rules of the game, and the system then proceeds on the basis of experiment. In this way, the program developed tactics to beat even the grand masters. In the beginning, the computer had very little experience of the game. It made the same mistakes as beginners by not looking far enough ahead. In fact, during the first matches, the computer simply placed stones randomly. When this tactic repeatedly resulted in a loss, the algorithm gradually adapted its tactics. Because the games all take place in the computer's ‘brain’, this process happens extremely rapidly, with AlphaGo Zero progressing in huge leaps.
The computer program eventually discovered the secret of the game and managed to take its game to the very top. 'You can see it rediscovering thousands of years of human knowledge', said DeepMind CEO Demis Hassabis during a press conference yesterday.
Folding proteins
That fact that AlphaGo teaches itself is key to using artificial intelligence in other fields. This is because the extensive datasets needed for system training are often lacking. It's much easier if the program can teach itself.
One of the examples that DeepMind mentioned is folding proteins. The large molecules in our bodies control all sorts of processes. The interactions between the molecules are extremely complicated, partly due to the way they are folded. Pharmacologists are trying to figure out the effect of certain folds so they can develop more targeted medicines. However, there is very little data available on folding proteins, making it difficult to train an algorithm using human knowledge. A self-taught algorithm solves that problem, at least in theory.
Rules programmed in
However, in practice, the results could be disappointing. Although the Go algorithm started with no understanding of the tactics of the game, there was a certain basic knowledge. The rules of the game were programmed in, so that the computer at least knew what was possible and what not. This would seem logical, but it causes problems in other specialist fields. We do not know, for instance, the precise rules of the game when it comes to folding proteins. What is and is not permitted, and what the consequences are exactly, is still unclear. Some doubt remains therefore as to whether or not the AlphaGo algorithm really has the potential to be useful while based on so little advanced knowledge. What's more, contrary to a Go board, proteins are three-dimensional. And that makes the problem a whole lot more complicated.
But that doesn't mean AlphaGo Zero's achievement is any less impressive. The program went from beginner to superhuman grand master in forty days, after playing 30 million games of Go. It discovered tactics that no human has ever thought of, and soundly defeated its computer predecessor, which used human knowledge. But DeepMind also adapted and partially simplified the algorithm. The predecessor used two separate programs, one to come up with a move and one to compute whether or not that move would lead to a win in future. AlphaGo Zero uses just one algorithm, which calculates directly after a move whether or not that move was good enough.
Partly due to the simpler algorithm, it requires less heavy-duty hardware. Although AlphaGo Zero needs a huge amount of computing power, it's still ten times less than the previous AlphaGo. And its training time was significantly shorter too.
This news confirms the growth rate of artificial intelligence. Just a couple of years ago, informatics still imagined that Go would either never be won by a computer or only in the distant future, but there is now a super computer that can beat every Go player on earth with very little advanced knowledge, and after just one month of training.
Did you like this article? Subscribe to our weekly newsletter.
Top image: Brian Jeffery Beggerly







Reacties