
Zelflerende Go-computer is nog beter
Een Go-computer die uit zichzelf het spel leert, blijkt nog beter te zijn dan een kunstmatige intelligentie die van mensen leerde. Google-bedrijf Deepmind bouwde zo'n zelflerende computer, die vervolgens met 100-0 won van zijn voorganger AlphaGo.
Eerder dit jaar won AlphaGo nog overtuigend van de beste menselijke Go-speler ter wereld (lees: 'Monsterzege voor Go-spelende computer'). Dat programma trainde met data van ruim 100.000 door mensen gespeelde Go-wedstrijden, en ontwikkelde aan de hand daarvan zijn eigen tactiek.
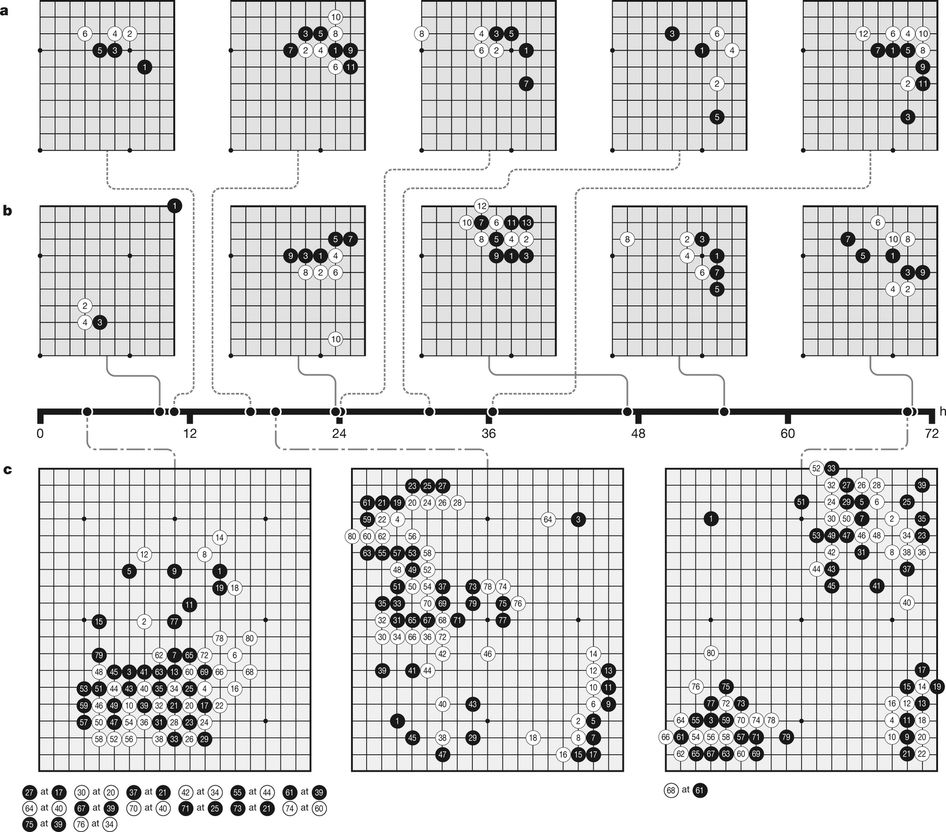
Het nieuwe algoritme, dat Deepmind AlphaGo Zero noemt, pakt het anders aan. Het heeft enkel de regels van Go ingeprogrammeerd gekregen, en gaat vervolgens zelf experimenteren. Op die manier ontwikkelde het programma tactieken om zelfs de grootmeesters te verslaan. In het begin had de computer nog maar weinig kaas gegeten van het spel. Hij maakte dezelfde fouten als beginners door niet naar de lange termijn te kijken. Sterker nog: in de allereerste pojtes legde de computer willekeurig stenen neer. Toen bleek dat die tactiek telkens tot verlies leidde, paste het algoritme langzaam maar zeker zijn tactiek aan. Omdat de spelletjes allemaal in het brein van de computer plaatsvonden ging het razendsnel en maakte AlphaGo Zero grote sprongen.
Uiteindelijk ontdekte het computerprogramma het geheim van het spel en wist het tot grote hoogten te reiken. 'Je ziet hem de duizenden jaren kennis over Go herontdekken', aldus Deepmind-CEO Demis Hassabis tijdens een persconferentie gisteren.
Eiwitten vouwen
Dat AlphaGo zelf leert is belangrijk om kunstmatige intelligentie in andere velden toe te passen. Er is namelijk niet altijd een uitgebreide dataset beschikbaar om mee te trainen. Het is dan handiger als een programma zelf kan leren.
Eén van de voorbeelden die Deepmind noemt is het vouwen van eiwitten. In ons lichaam regelen grote moleculen allerhande processen. De interacties tussen die moleculen zijn erg ingewikkeld, mede door de manier waarop ze gevouwen zijn. Farmacologen proberen het effect van bepaalde vouwingen uit te vogelen om zo gerichter medicijnen te kunnen ontwikkelen. Er is echter maar weinig data beschikbaar over vouwende eiwitten, dus dat maakt het lastig om een algoritme te trainen aan de hand van menselijke kennis. Een zelflerend algoritme lost dat in theorie op.
Regels ingeprogrammeerd
In de praktijk kan dat echter tegenvallen. Dit zelflerende Go-algoritme begon weliswaar zonder kennis over de speltactieken, maar had wel een zekere basiskennis. De regels van het spel waren ingeprogrammeerd, zodat de computer in ieder geval wist wat wel en niet mogelijk was. Dat lijkt logisch, maar in andere vakgebieden levert dat problemen op. We kennen bijvoorbeeld niet de precieze regels die gelden bij het vouwen van eiwitten. Wat wel en niet mag, en wat de precieze gevolgen zijn, is onduidelijk. Het is de vraag of een AlphaGo-algoritme ook met zo weinig voorkennis nog nuttig kan zijn. Bovendien zijn eiwitten driedimensionaal, in tegenstelling tot een Go-bord. Dat maakt het probleem veel ingewikkelder.
Maar het maakt de prestatie van AlphaGo Zero niet minder knap. Het programma ging van beginner naar bovenmenselijke grootmeester in veertig dagen, na het spelen van 30 miljoen potjes Go. Het ontdekte tactieken waar mensen nooit aan zouden denken, en versloeg zijn computervoorganger – die van mensenkennis uitging – overtuigend. Daarnaast heeft Deepmind het algoritme aangepast en deels versimpeld. De voorganger gebruikte twee aparte programma's, één om een zet te bedenken en één om te kijken of die zet in de toekomst naar winst zou leiden. AlphaGo Zero gebruikt maar één algoritme, dat na het bedenken van een zet meteen nadenkt of de zet goed genoeg is.
Mede door dat simpeler algoritme is er ook minder zware hardware nodig. AlphaGo Zero vereist een hoop rekenkracht, maar wel tien keer minder dan de vorige AlphaGo. Bovendien was de trainingstijd aanzienlijk korter.
Het nieuws is een bevestiging van de groeisnelheid van kunstmatige intelligentie. Waar de informatica een paar jaar terug nog dacht dat Go nooit of pas over lange tijd door een computer gewonnen kon worden, is er nu een supercomputer die met nauwelijks menselijke kennis iedere Go-speler ter wereld overtreft, na iets meer dan een maand trainen.
Beeld: Brian Jeffery Beggerly







Reacties